
Embeddingy 101: Ako funguje vyhľadávanie podľa významu, nie slov
Popis embeddingov je celkom jednoduchý. Vieme dať ľubovoľnému textu „číslo“, ktoré reprezentuje jeho význam. Poďme si povedať, ako to reálne funguje a aké sú implikácie pri vyhľadávaní.
Priznám sa, že keď som spomínal „číslo“ je to len zjednodusenie a nie je to úplne pravda. Embeddingy sa reprezentujú cez vektory. Vektory sú šípky, ktoré majú smer a dĺžku.
Keďže embeddingy reprezentujeme cez vektory, vieme nad nimi robiť operácie. A to je pre nás hlavne sčítanie, odčítanie a porovnávanie pozície.
Teda vieme povedať, ako blízko sú dva vektory pri sebe. Alebo môžeme zobrať jeden vektor, odčítať od neho druhý a dostať ako výsledok nový vektor.
Toto je koniec matematického okienka, a ideme na priklady.
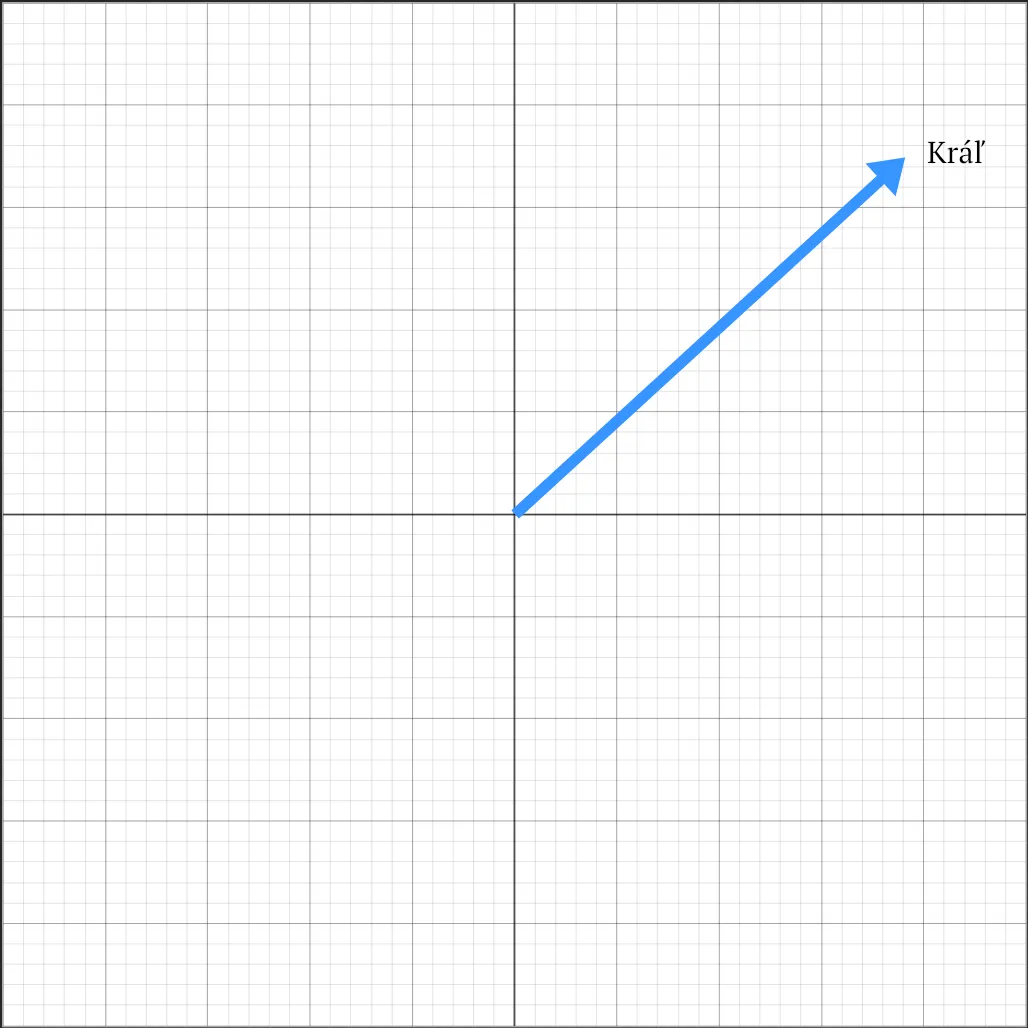
Vektor, ktorý vidíme, reprezentuje slovo „Kráľ“ – jeho význam v každom smere, ako ho chápeme my. Kráľ je muž, ktorý sedí na tróne, figúrka v šachu, karta v pokri atď. Všetky tieto významy sú reprezentované šípkou, ktorú vidíte na obrázku.
Pridajme si ďalšiu šípku, ktorá reprezentuje slovo „Kráľovna“, taktiež vo všetkých významoch.
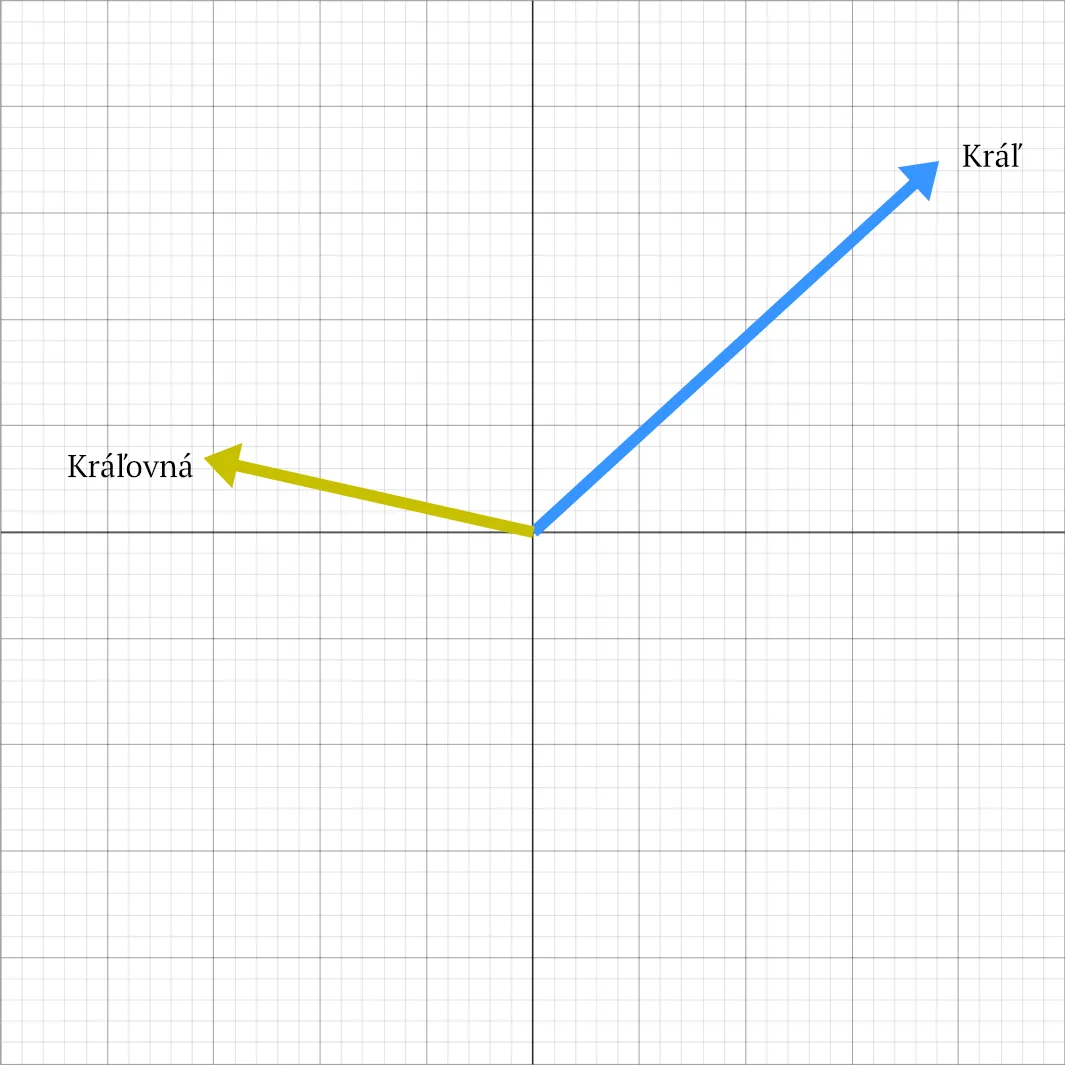
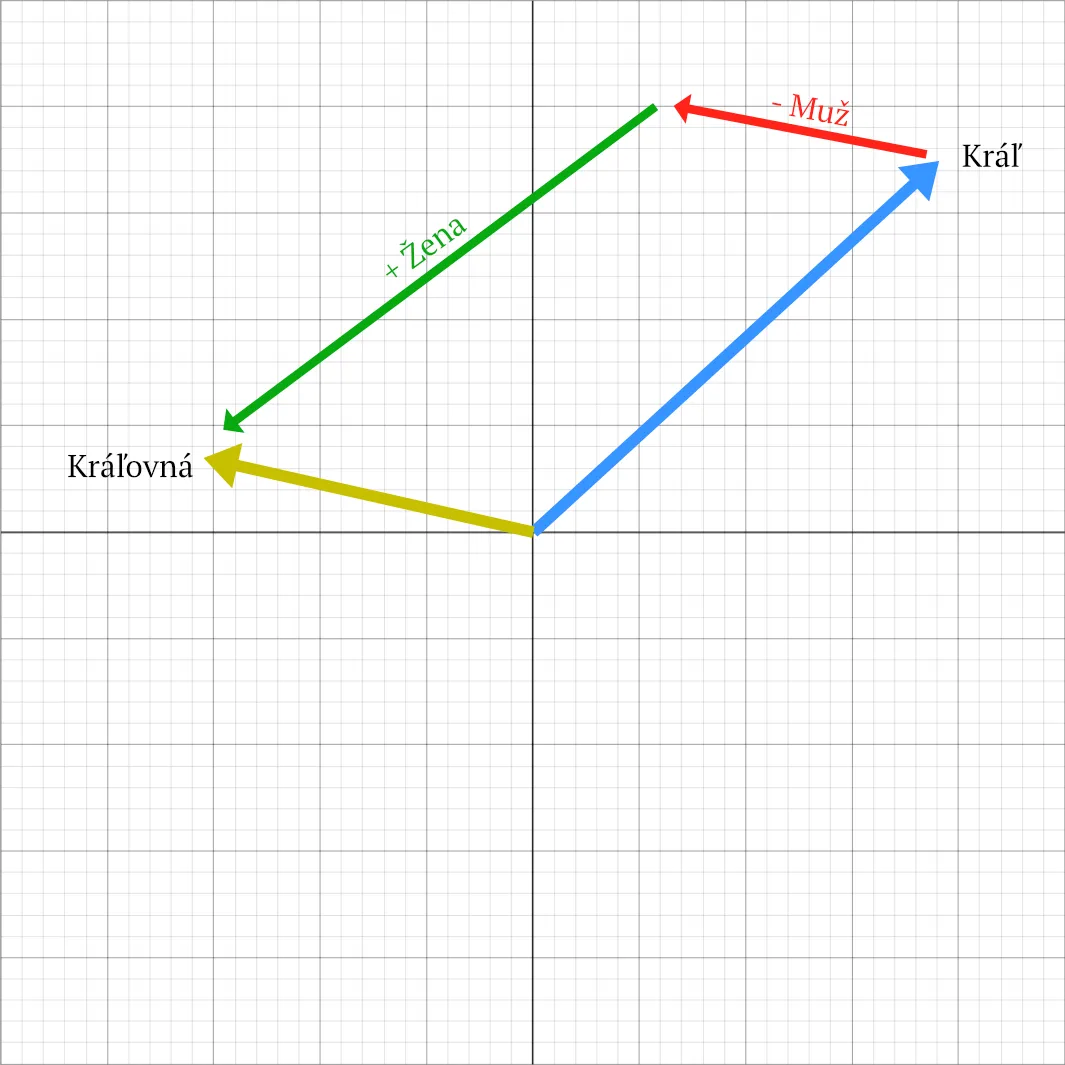
No a keďže vieme robiť matematické operácie s vektormi, môžeme skúsiť, čo sa stane, ak budeme odpočítavať a pripočítavať koncepty. Ak od slova „Kráľ“ odpočítame „Muž“ a pripočítame „Žena“, dostaneme „Kráľovna“. Tento princíp funguje pri všetkých slovách a zachytáva prekvapivo veľa vzťahov, ktoré si normálne ani neuvedomujeme.
Môj obľúbený príklad je, keď zoberieme „mňau“, odpočítame „mačka“ a pripočítame „Santa“, dostaneme „ho ho ho“.
Taktiež vieme zobrať šípku pre slovo „pes“ a zistiť, aké sú najbližšie podobné šípky (slová). Pre „pes“ to budú napríklad „psy“, „psík“, „domáci miláčik“, „buldog“ atď. Týmto istým spôsobom vieme zobrať dve slová a povedať, ako sú od seba ďaleko, resp. ako veľmi sú si podobné. Čím sú bližšie, tým sú si podobnejšie. Napríklad „mačka“ a „pes“ sú omnoho bližšie než „mačka“ a „auto“.
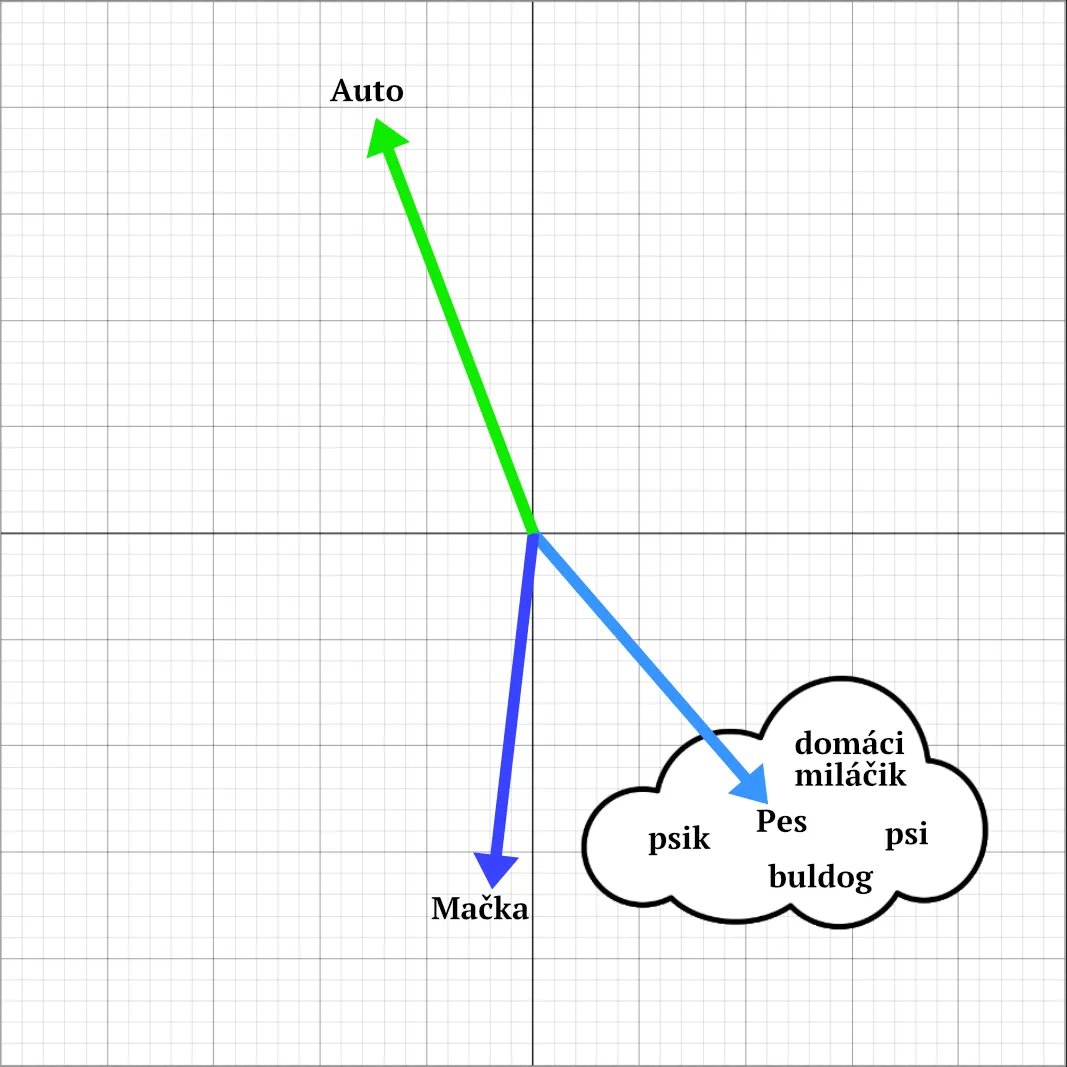
Nevieme presne povedať, či sú slová totožné, ale vieme určiť, ako blízko alebo ďaleko sú od seba na škále od 0 po 1. Čím je číslo menšie, tým sú slová bližšie pri sebe a môžeme povedať, že sú významovo podobné, resp. že reprezentujú podobný koncept.
V našom konkrétnom príklade to funguje tak, že zoberieme celý paragraf a vytvoríme z neho vektor. Tento vektor si následne uložíme. Rovnaký proces spravíme pre všetky paragrafy a texty vo všetkých zákonoch. Keď potom používateľ niečo vyhľadáva, vytvoríme vektor z jeho dopytu a pozrieme sa, ktoré vektory sú mu najbližšie. Napríklad, ak zadáme vyhľadávanie „balkón ako spoločná časť domu“, nájdeme ako najbližší text odseky (1 a 3) § 10 zákona číslo 182/1993.
Treba však podotknúť – ako bolo vidieť na príklade s kráľom –, že význam je zaznamenaný vo viacerých zmysloch. To znamená, že na praktické využitie treba používať viac filtrovania, ale aj tak dostávame veľmi relevantné výsledky.
Ešte pár poznámok na záver:
- Treba si uvedomiť, že postup prekladu textu na vektor závisí od embedding modelu, ktorý používame. Každý model teda bude mať iný výsledok.
- V príkladoch sme používali 2D vektory na jednoduché ukázanie princípu. V praxi však nie je možné každé slovo presne lokalizovať v takto jednoduchom priestore. Preto sa používajú omnoho väčšie vektory (s viacerými dimenziami). Napríklad v prípade OpenAI modelov ide konkrétne o 3072 dimenzií.
- V texte sme spomínali, že vytvoríme embedding z paragrafu. To však nie je vždy možné, ak je paragraf príliš dlhý – vtedy ho treba správne rozdeliť ešte pred embedovaním a zároveň upraviť spôsob vyhľadávania, aby sme dosiahli správne výsledky.
- Taktiež treba dávať pozor na to, ak sa na začiatku dokumentu nachádzajú dôležité informácie o jeho význame. Je potrebné zabezpečiť, aby sa tieto informácie “preniesli” aj do textov na konci dokumentu. Inak by sme pri vyhľadávaní niektoré odseky vôbec nenájsť, keďže informácie zo začiatku dokumentu by sa sa vo vektori nenachádzali.
- A omnoho viacej…
Dúfam, že som vám týmto dal dobrý prehľad o embeddingoch a o tom, ako sa využívajú.
Ak máte otázky, pokojne mi píšte – rád odpoviem. A ak si chcete embeddingy v praxi vyskúšať, navštívte app.praktik.ai.